Guide
Configure Onyx to use models served by Ollama.1
Setup Ollama and Deploy your Models
The Ollama GitHub repository
details how to download and deploy models on Ollama.If self-hosting, Ollama is configured to run on port
11434 by default.You can also configure Onyx to use Ollama’s managed cloud service.2
Navigate to AI Model Configuration Page
Access the Admin Panel from your user profile icon → Admin Panel → LLM
3
Configure Ollama
Select Ollama from the available providers.Give your provider a Display Name.If using Ollama Cloud, enter your Ollama Cloud API Key.Click the Fetch Available Models button to see the models available in your Ollama instance.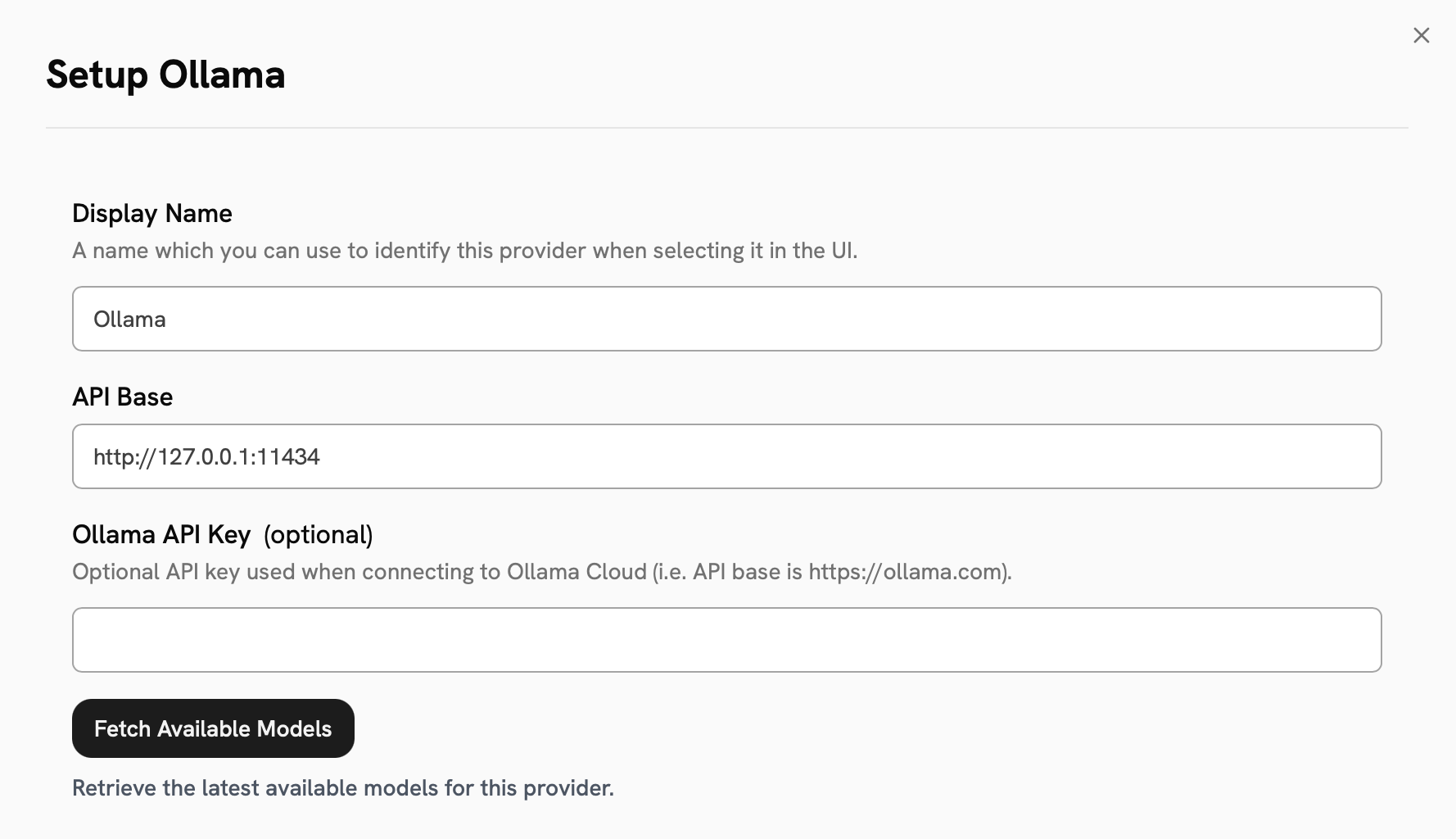
4
Configure Default and Fast Models
The Default Model is selected automatically for new custom Agents and Chat sessions.Designating a Fast Model is optional.
This Fast Model is used behind the scenes for quick operations such as evaluating the type of message,
generating different queries (query expansion), and naming the chat session.
If you select a Fast Model,
make sure it is a relatively quick and cost-effective model like GPT-4.1-mini or Claude 3.7 Sonnet.
5
Choose Visible Models
In the Advanced Options, you will see a list of all models available from this provider.
You may choose which models are visible to your users in Onyx.Setting visible models is useful when a provider publishes multiple models and versions of the same model.
6
Designate Provider Access
Lastly, you may select whether or not the provider is public to all users in Onyx.If set to private,
the provider’s models will be available to Admins and User Groups you explicitly assign the provider to.